INTRODUCING
TACHYON
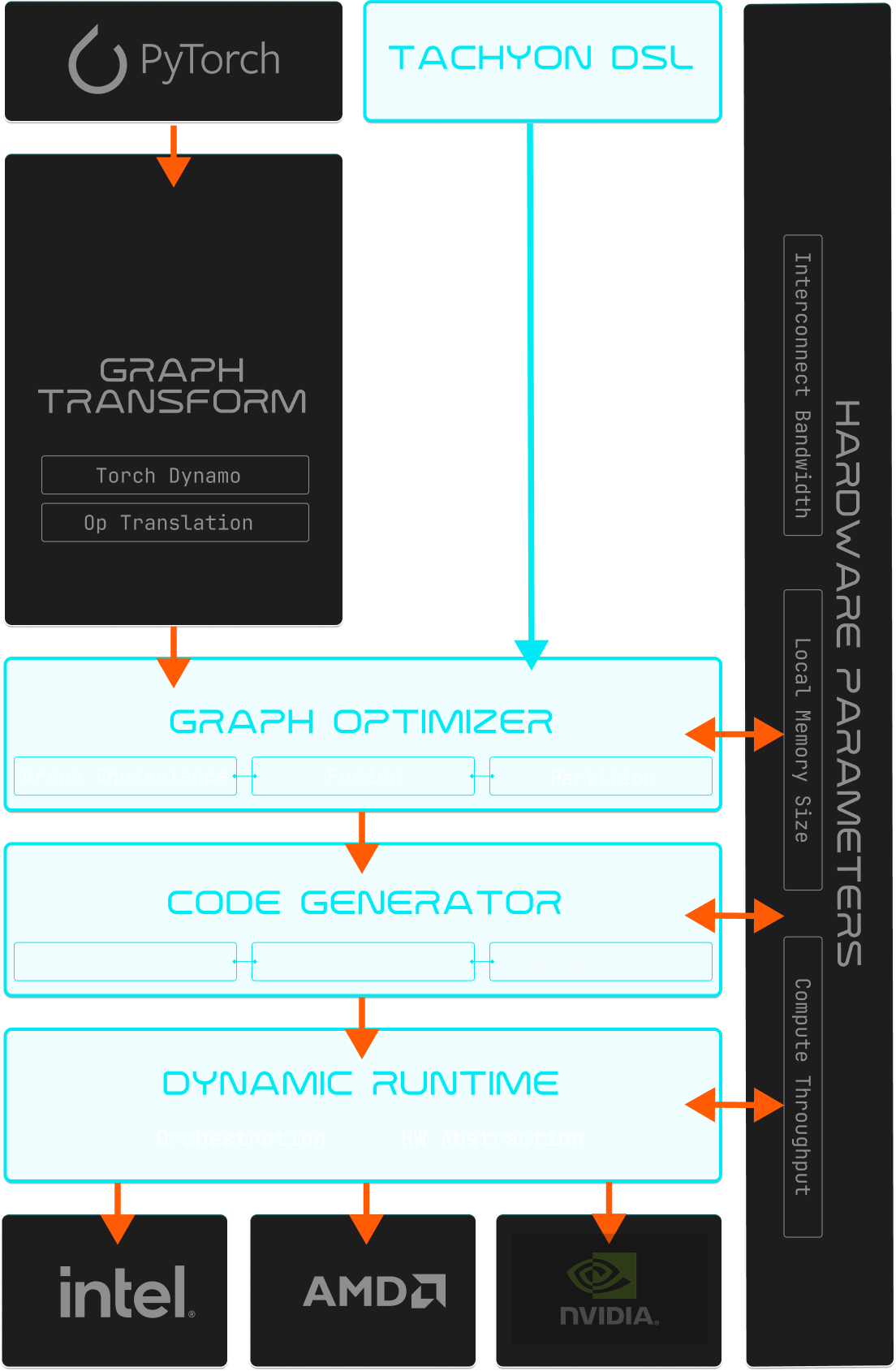
5 COMPONENTS MAKE IT POSSIBLE:
We built a complete stack that lets you program your entire system - from a single device to thousands of nodes - as a unified whole.

TACHYON DSL
A pythonic tensor language that helps you get the most out of the compiler and express the entire end to end AI pipeline.
Hardware-Independent Concurrent IR
Represents computation using parallel programming primitives that explicitly capture concurrency and data flow.
Hardware-Parameterized Graph Optimizer
Restructures your computation to maximize data re-use, minimize data movement, and eliminate synchronization barriers. Uses detailed hardware information—memory sizes, bandwidth, topology—to automatically partition work optimally across whatever system you're running on. One device or a thousand, same code, optimal partitioning.
Portable Optimizing Code Generator
Generates high-performance object code for any target hardware. Takes hardware characteristics as parameters, so the same compilation pipeline works for NVIDIA, AMD, Intel, etc.
Hierarchical Dynamic Runtime
Explicitly manages data movement and orchestrates execution across your entire cluster. Overlaps communication with computation. Adapts dynamically to changing runtime conditions.
WHY THIS APPROACH WORKS
Parallel compilation beats serial compilation for parallel workloads:
Traditional compilers try to extract parallelism from serial code. We start with explicitly parallel representations, which lets our compiler reason about concurrency, fusion, and partitioning directly instead of trying to infer it.Not locked into any vendor. Use the hardware that makes the most sense for your model and business.
Communication-optimal code beats compute-optimal code:
Kernel libraries optimize individual operations, such as making some matmul as fast as possible. We optimize data flow across operations to minimize data movement, overlap transfers with computation. When data starvation is the bottleneck, communication-optimal wins.You no longer need armies of performance engineers spending all their time writing kernels and porting from platform to platform. Your AI engineers get back to focusing on what matters, not wrestling their infrastructure.
Dynamic adaptation beats static schedules:
Large systems are non-deterministic. Latencies vary. Execution times vary. Static kernel schedules make fixed assumptions that break under real conditions. Our dynamic runtime adapts continuously to what's actually happening.Need more capacity, just add GPUs and recompile. Want to switch to new hardware, just do it. The same code runs everywhere.Plug‑in model supports new accelerators in <90 days.
Hardware-aware compilation beats hardware-agnostic abstraction:
We don't abstract over hardware—we reason about it explicitly. Memory sizes, bandwidth, vector instruction shapes, cache behaviors. This is how we generate optimal code for any target without the performance penalty of traditional abstraction layers.
Explicit data management beats cache-based approaches:
We don't rely on unpredictable cache mechanisms. We explicitly control where data lives and when it moves. This reduces non-determinism and enables latency hiding—the runtime pre-stages data before it's needed.We don't abstract over hardware—we reason about it explicitly. Memory sizes, bandwidth, vector instruction shapes, cache behaviors. This is how we generate optimal code for any target without the performance penalty of traditional abstraction layers.
WHAT YOU GET
Freedom to choose hardware based on economics
Not locked into any vendor. Use the hardware that makes the most sense for your model and business.
Your team stays focused on your product
You no longer need armies of performance engineers spending all their time writing kernels and porting from platform to platform. Your AI engineers get back to focusing on what matters, not wrestling their infrastructure.
Predictable scaling
Need more capacity, just add GPUs and recompile. Want to switch to new hardware, just do it. The same code runs everywhere.
Dramatically lower costs
60-80% reduction in serving costs from higher utilization.